Why dnamite
This user guide will give an overview of dnamite and its use cases.
Methods
Additive Models
dnamite is a package for additive models. Additive models take the form:
where the link function \(g\) depends on the supervised learning task. Additive models generalize linear models by allowing each feature function \(f_j\), known as a shape function, to be nonlinear, thereby capturing arbitrarily complex patterns. Additive models enjoy many of the benefits of linear models but can provide significantly more accuracy. First, because additive models preserve additive structure, plotting \(\hat{f}_j\) visualizes the exact contribution of \(X_j\) to the final (unlinked) prediction. Second, averaging \(|\hat{f}_j|\) across the training data gives a natural importance score for feature \(j\), allowing for easy assessment of the most important features.
DNAMite Architecture
The dnamite package trains Neural Additive Model (NAMs), i.e. additive models that use neural network for each shape function. The package specifically uses the eponymous DNAMite architecture, which is summarized below.

The DNAMite architecture has two key advantages over other NAM architectures. First, DNAMite seamlessly handles categorical features as well as missing values without any preprocessing. Second, many NAM architectures produce overly smooth shape functions, while DNAMite’s embedding module can directly control the smoothness of shape functions. As a result, DNAMite’s shape functions often represent true shape functions more accurately than other NAMs. See the below exactly taken from [1].
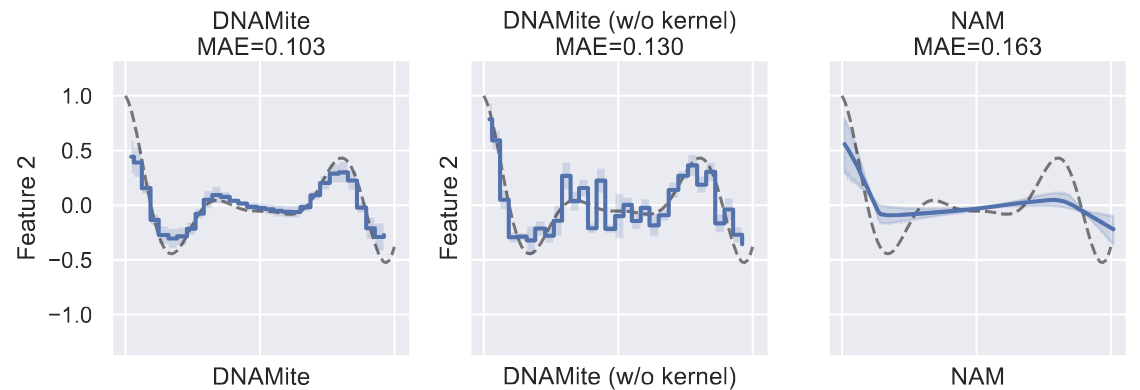
[1] Van Ness, M., Block, B. & Udell, M.. (2025). DNAMite: Interpretable Calibrated Survival Analysis with Discretized Additive Models. Proceedings of the 4th Machine Learning for Health Symposium, in Proceedings of Machine Learning Research 259:805-823 Available from https://proceedings.mlr.press/v259/van-ness25a.html.
Why Care about Interpretability?
There’s a lot of debate amongst researcher and practitioners about when interpretability is actually useful. For example, this blog post is one example of recent work suggesting that interpretability is less important than advertised. Further, it’s critical to keep in mind that model interpretations always represent correlations which may or may not be causal, so interpretable machine learning is never a replacement for causal inference. Nonetheless, we believe that using interpretable machine learning models like DNAMite is still very valuable for many reasons.
Understanding Predictions, Good and Bad
When using a glass-box model like DNAMite, we know with 100% confidence how each feature contributes to each prediction. For cases when the model does well, this knowledge can be useful for explaining why the model is able to predict accuracy. For example, after deploying a new machine learning model, showcasing examples when the new model outperforms the previous model is more effective if it is easy to explain how/why the new model does better (e.g. the new model effectively utilizes new features). On the other hand, identifying which features cause a bad prediction can help with understanding why the model is underperforming and how it could potentially be improved.
Model Auditing
Understanding how a model is making predictions at a macro level can be crucial for validating model generalizability. For example, in one hospital network, visitation by a priest may be a strong predictor of mortality, but this feature may not be available in other hospital networks. Thus, if this feature’s importance score is high, it may be worth removing the feature so that the model learns from features that are more likely to be widely available. This type of model auditing is simply not possible when using black-box models which can result in unexpected poor generalizability. Further, interpretable models can be more easily audited to look for other potentially concerns such as fairness and privacy.
Making Discoveries
While interpretable models cannot be used for identifying causal relationships, they can be used to discover patterns in the data. In this way, such models can be viewed as a very powerful tool for exploratory data analysis. If a new pattern is discovered in the data, this could be used to provoke further investigation into a potential causal relationship.
Instilling Trust
People generally are more likely to believe a model’s prediction if the model can explain how it came up with the prediction [1]. Thus, in settings where users may be weary of model predictions, an interpretable model can help instill trust that the model is not deviating significantly from existing intuition.
[1] Poursabzi-Sangdeh, Forough, et al. “Manipulating and measuring model interpretability.” Proceedings of the 2021 CHI conference on human factors in computing systems. 2021.
When Should I Use DNAMite?
For some use cases, the R package mgcv or the Python package interpreml have similar utility to dnamite. However, here are three use cases in which dnamite is particularly useful compared to other additive model packages:
Sparse Datasets: given a dataset with many missing values, most other additive model packages will require imputation before model training. dnamite models, meanwhile, do not require imputation before training. Instead, dnamite’s shape functions learn a separate value when a feature is missing. These missing scores can be visualized when plotting feature importances using the
missing_binparameter in each model’splot_feature_importancesfunction.Survival Analysis: in survival analysis, the goal is to predict the distribution of a time-to-event random variable. Neural networks are widely used for survival analysis as they can easily produce multi-dimensional outputs useful for learning the entire time-to-event distribution. DNAMite, thus, naturally can be used for survival analysis, while tree-based models like EBM from interpretml are much harder to adapt for survival analysis. For more details see the Survival Analysis User Guide.
Feature Selection: when a dataset has many features, it makes it much harder for the model to attribute importance to any individual features. In such settings, it is desirable to learn a model that is both interpretable and feature-sparse. Since interpretml and other similar packages do not support any feature selection/sparsity, using a different model for feature selection would be required, which can lead to suboptimality. Meanwhile, DNAMite can do both feature selection and interpretable prediction. For more details see the Feature Selection User Guide.